1 Introduction to Machine Learning
Machine learning (ML) continues to grow in importance for many organizations across nearly all domains. There’s no shortage of definitions for the term machine learning. For the purposes of this book, we can think of it as a blended field with a focus on using algorithms to help learn from data. This process of learning from data results in a model, which we can use to make predictions.
Some example applications of machine learning in practice include:
- Predicting the likelihood of a patient returning to the hospital (readmission) within 30 days of discharge.
- Predicting songs to recommend to listeners on a music app.
- Predicting the estimated travel time to drive from your home to work.
- Predicting a segmentation that a customer aligns to based on common attributes or purchasing behavior for targeted marketing.
- Predicting coupon redemption rates for a given marketing campaign.
- Predicting customer (or employee) churn so an organization can perform preventative intervention.
- And many more!
In essence, these tasks all seek to learn and draw inferences from patterns in data. To address each scenario, we can use a given set of features to train an algorithm and extract insights. These algorithms, or learners, can be classified according to how they learn to make predictions and the four main groups of learners are:
- Supervised learning
- Unsupervised learning
- Reinforcement learning
- Generative artificial intelligence (AI)
Which type you will need to use depends on the learning task you hope to accomplish; and the primary focus of this book is on the first two groups of learners - supervised and unsupervised learning.
1.1 Supervised learning
Supervised learning is a set of ML learners that learn the relationship between inputs (often referred to as features or predictors) and output(s) (often referred to as the target variable). Or, as stated by Kuhn and Johnson (2013, 26:2), supervised learning is “…the process of developing a mathematical tool or model that generates an accurate prediction.” The learning algorithm in a supervised learning model attempts to discover and model the relationships among the target variable (the variable being predicted) and the other features. Examples of predictive modeling include the following:
- Using customer attributes (e.g., age and recent shopping behavior) to predict the probability of the customer churning in the next 6 weeks.
- Using various home attributes to predict the sales price.
- Using employee attributes to predict the likelihood of attrition within the next six months.
- Using patient attributes and symptoms to predict the risk of being readmitted to the hospital within 30 days after release.
- Using product attributes to predict time to market.
- Using weather conditions and relevant historical information to predict the number of bikes that will be rented out on a given day.
Each of these examples has a defined learning task; they each intend to use various features (\(X\)) to predict a well-defined target (\(Y\)). Think about the hospital readmission example. Predicting the liklihood of readmittance is not specific enough and will make pulling together relevant data a challenge, so we need to think carefully aabout how we define the features and response for modeling. Defining the target as whether or not a patient was readmitted within 30 days after release is something that can easily be measured, assuming it’s relevant to the stakeholders.
The scenarios listed above are examples of supervised learning. The supervision refers to the fact that the target values provide a supervisory role, which indicates to the learner the task it needs to learn. Specifically, given a set of data, the learning algorithm attempts to optimize a function (the algorithmic steps) to find the combination of feature values that results in a predicted value that is as close to the actual target output as possible.
In supervised learning, the training data you feed the algorithm includes the target values. Consequently, the solutions can be used to help supervise the training process to find the optimal algorithm parameters, called hyperparameters.
Most supervised learning problems can be bucketed into one of two general categories, regression or classification, depending on the type of response variable. We’ll briefly discuss both cases over the next two sections.
Throughout this text we’ll use various terms and notation interchangeably. In particular,
- we’ll use \(X\) to denote a feature, predictor, or attribute (we may even use the more classic term independent variable);
- bold notation may be used to denote a set of features, for example \(\boldsymbol{X} = \left(X_1, X_2\right)\), where, in the case of the predicting sale price example, \(X_1\) might represent square footage and \(X_2\) represent the overall quality of the home;
- we’ll use \(y\) when referring to response or target variable (again, we may sometimes use the more classic term dependent variable).
1.1.1 Regression problems
When the objective is to predict a quantitative outcome, we generally refer to this as a regression problem (not to be confused with linear regression modeling, which is a special case). Regression problems revolve around numeric output where both order and distance matters (e.g., sales or a discrete count, like the number of bike rentals in a given day). In the examples above, predicting home sale prices based home attributes is a regression problem because the output is ordered and values closer to each other are closer in nature (e.g., the closer two sale prices are to each other the more similar the homes are in terms of sale value).
Figure 1.1 shows a regression model’s predicted sale price of homes in Ames, Iowa (from 2006–2010) as a function of two attributes: year built and total square footage. Depending on the combination of these two features, the expected home sales price could fall anywhere along the surface.
See Table 1.1 for a few more examples of regression models:
| Scenario | Potential features | Numeric prediction |
|---|---|---|
| Predict home prices | Square footage, zip code, number of bedrooms and bathrooms, lot size, mortgage interest rate, property tax rate, construction costs, and number of homes for sale in the area. | The home price in dollars. |
| Predict ride time | Historical traffic conditions (gathered from smartphones, traffic sensors, ride-hailing and other navigation applications), distance from destination, and weather conditions. | The time in minutes and seconds to arrive at a destination. |
| Predict loan interest rate | Customer credit score, number of loans outstanding, historical repayment history, size of loan requested, current inflation and treasury rates. | The interest rate to be applied to a loan. |
We’ll learn various ways of building such a model in Part II of this book (TODO: cross-reference “Part II”).
1.1.2 Classification problems
When the objective of our supervised learning is to predict a qualitative (or categorical outcome), we refer to this generally as a classification problem. Classification problems most commonly revolve around predicting a binary or multinomial response measure such as:
- Predicting if a customer will redeem a coupon (coded as yes/no or 1/0)?
- Predicting if a customer will churn (coded as yes/no or 1/0)?
- Predicting if a customer will click on our online ad (coded as yes/no or 1/0)?
- Predicting if a customer review is:
- Binary: positive vs. negative.
- Multinomial: extremely negative to extremely positive on a 0–5 Likert scale.
However, when we apply ML models to classification problems, rather than predict a particular class (i.e., “yes” or “no”), we often want to predict the conditional probability of a particular class (i.e., yes: 0.65, no: 0.35).1 By default, the class with the highest predicted probability becomes the predicted class (called a classification). Consequently, even though we classify it as a classification problem (pun intended), we’re often still predicting a numeric output (i.e., a probability). However, the nature of the target variable is what makes it a classification problem.
Table 1.2 illustrates some example classification predictions where the model predicts the conditional probability of “Yes” and “No” classes. A threshold of 0.5 probability is used to determine if the predicted class is “Yes” or “No”.
| Predicted “Yes” probability | Predicted “No” probability | Predicted class |
|---|---|---|
| 0.65 | 0.35 | Yes |
| 0.15 | 0.85 | No |
| 0.43 | 0.57 | No |
| ⋮ | ⋮ | ⋮ |
| 0.72 | 0.28 | Yes |
Throughout this book we will commonly use the term classification for brevity; however, the distinction between predicting the probability of an output and classifying that prediction into a particular class is important and should not be overlooked. Frank Harrell’s discussion on classification versus prediction (Harrell 2017) is an excellent read to delve deeper into this distinction, along with why and when we should be focusing on probability prediction over classification and vice versa.
Although there are ML algorithms that can be applied to regression problems but not classification and vice versa, most of the supervised learning algorithms we’ll cover in this book can be applied to both. These algorithms have become some of the most popular machine learning models in recent years (often driven by their availability in both proprietary and open-source software).
1.1.3 Knowledge check
1.2 Unsupervised learning
Unsupervised learning, in contrast to supervised learning, includes a set of statistical tools to better understand and describe your data, but performs the analysis without a target variable. In essence, unsupervised learning is concerned with identifying groups in a data set. The groups may be defined by the rows (i.e., clustering) or the columns (i.e., dimension reduction); however, the motive in each case is quite different.
The goal of clustering is to segment observations into similar groups based on the observed variables; for example, dividing consumers into different homogeneous groups, a process known as market segmentation.
Clustering differs from classification because the categories aren’t defined by you. For example, Figure 1.3 shows how an unsupervised model might cluster a weather dataset based on temperature, revealing segmentations that define the seasons. You would then have to name those clusters based on your understanding of the dataset.
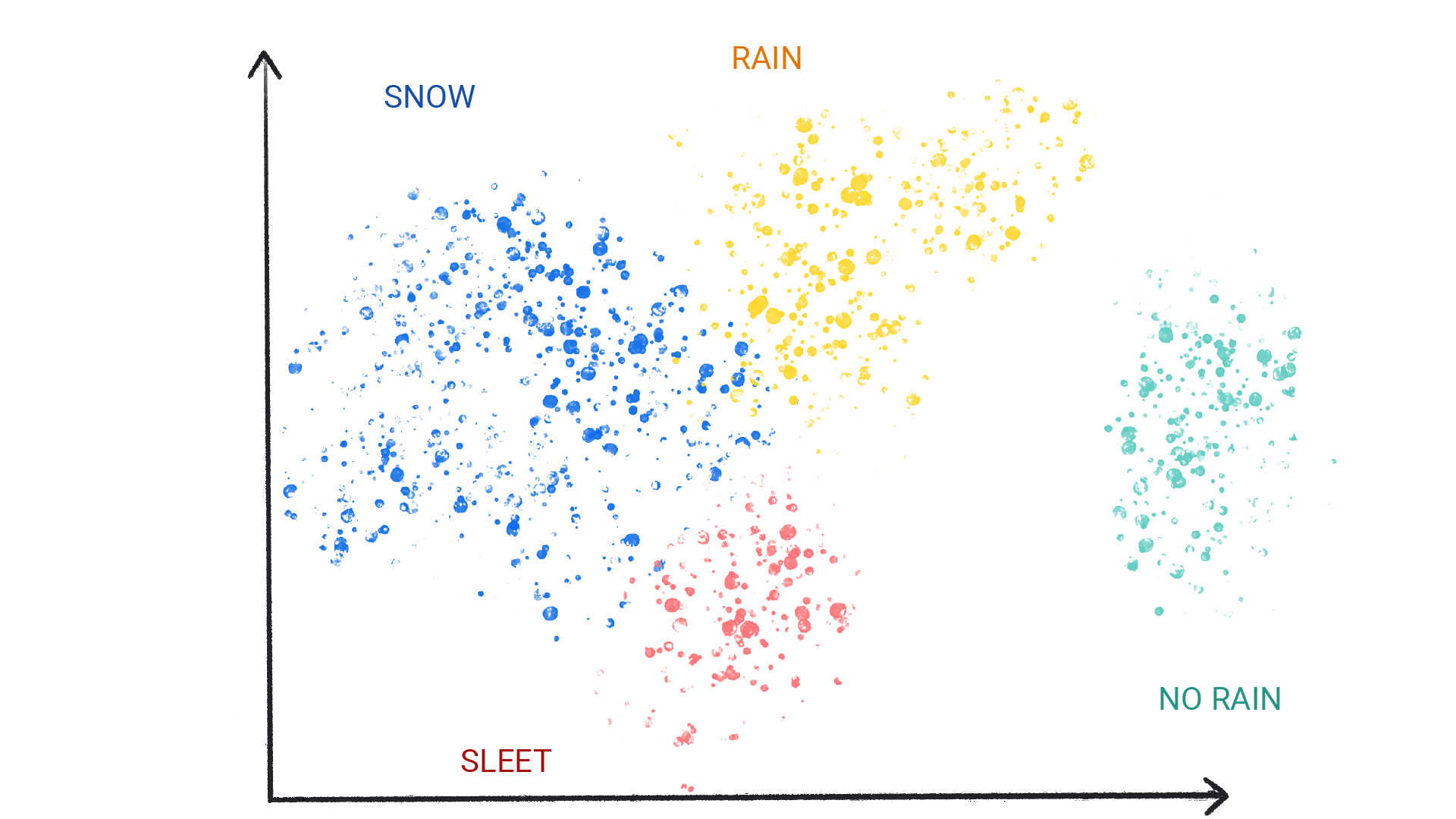
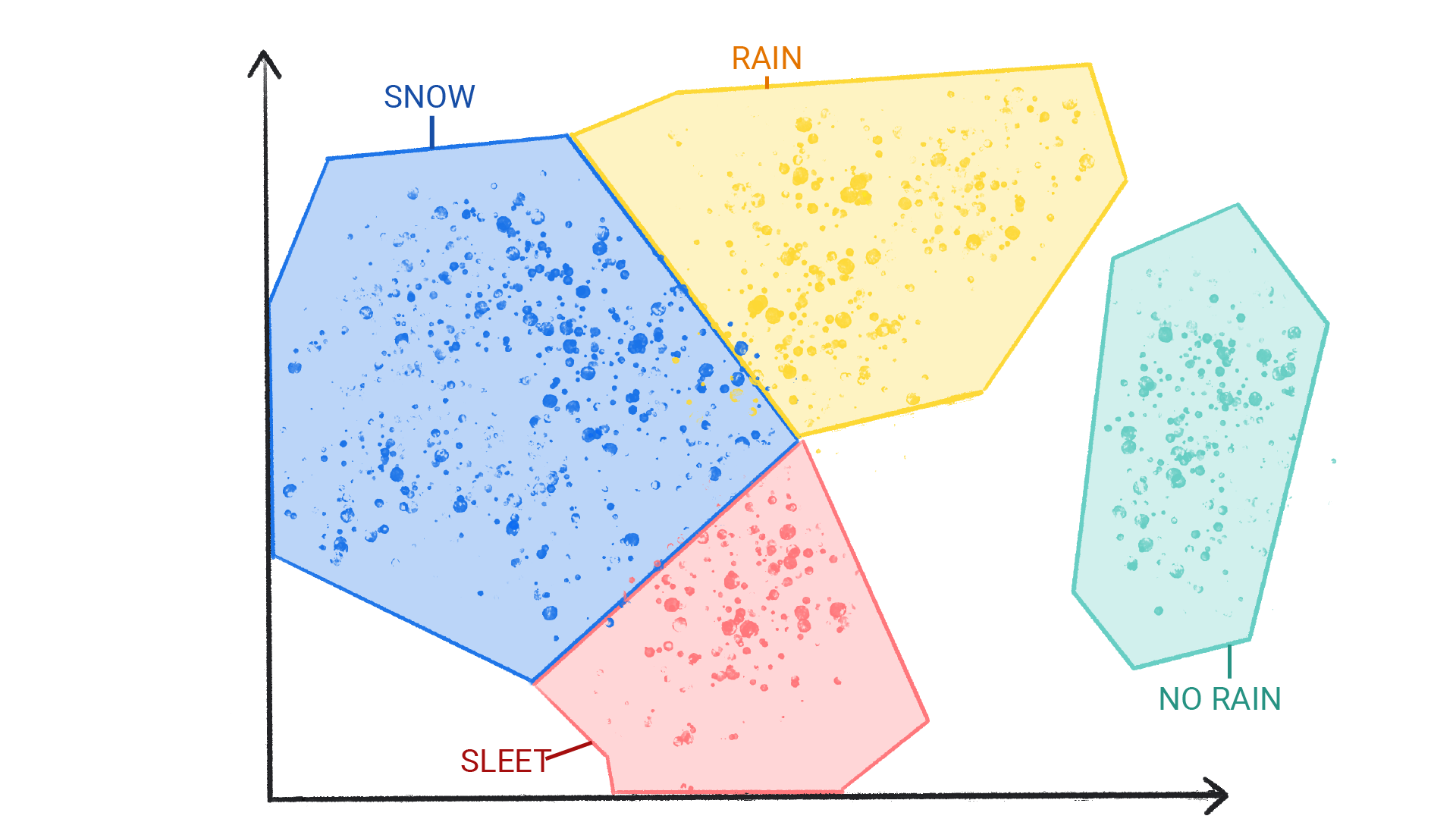
In dimension reduction, we are often concerned with reducing the number of variables in a data set. For example, classical linear regression models break down in the presence of highly correlated features, a situation known as multicollinearity.2 Some dimension reduction techniques can be used to reduce the feature set to a potentially smaller set of uncorrelated variables. Such a reduced feature set is often used as input to downstream supervised learning models (e.g., principal component regression).
Unsupervised learning is often performed as part of an exploratory data analysis (EDA). However, the exercise tends to be more subjective, and there is no simple goal for the analysis, such as prediction of a response. Furthermore, it can be hard to assess the quality of results obtained from unsupervised learning methods. The reason for this is simple. If we fit a predictive model using a supervised learning technique (e.g., linear regression), then it is possible to check our work by seeing how well our model predicts the response \(y\) on new observations not used in fitting the model. However, in unsupervised learning, there’s no way to check our work because we don’t know the true answer—the problem is unsupervised!
Despite its subjectivity, the importance of unsupervised learning should not be overlooked and such techniques are often used in organizations to:
- Divide consumers into different homogeneous groups so that tailored marketing strategies can be developed and deployed for each segment.
- Identify groups of online shoppers with similar browsing and purchase histories, as well as items that are of particular interest to the shoppers within each group. Then an individual shopper can be preferentially shown the items in which he or she is particularly likely to be interested, based on the purchase histories of similar shoppers.
- Identify products that have similar purchasing behavior so that managers can manage them as product groups.
These questions, and many more, can be addressed with unsupervised learning. Moreover, the outputs of unsupervised learning models can be used as inputs to downstream supervised learning models.
1.2.1 Knowledge check
1.3 Reinforcement learning
Reinforcement learning (RL) refers to a family of algorithms that learn to make predictions by getting rewards or penalties based on actions performed within an environment. A reinforcement learning system generates a policy that defines the best strategy for getting the most rewards.
This best strategy is learned through interactions with the environment and observations of how it responds. In the absence of a supervisor, the learner must independently discover the sequence of actions that maximize the reward. This discovery process is akin to a trial-and-error search. The quality of actions is measured by not just the immediate reward they return, but also the delayed reward they might fetch. As it can learn the actions that result in eventual success in an unseen environment without the help of a supervisor, reinforcement learning is a very powerful algorithm.
A few examples of RL include:
- Robotics. Robots with pre-programmed behavior are useful in structured environments, such as the assembly line of an automobile manufacturing plant, where the task is repetitive in nature. However, in the unpredictable real world, where the interaction between a robot’s actions and the environment is uncertain, achieving precise pre-programmed actions becomes exceedingly challenging. In such situations, Reinforcement Learning (RL) offers an effective approach to develop versatile robots. RL has demonstrated success in the context of robotic path planning, where robots need to autonomously discover optimal, obstacle-free, and dynamically compatible paths between two locations.
- AlphaGo. Go, a Chinese board game dating back 3,000 years, stands out as one of the most intricate strategic games known. Its complexity is attributed to the staggering number of possible board configurations, estimated at 10^270, surpassing the complexity of chess by several orders of magnitude. In 2016, AlphaGo, an artificial intelligence agent based on Reinforcement Learning (RL), achieved victory against the world’s top human Go player. Much like a human player, AlphaGo learned through experience, engaging in thousands of games against professional opponents. Notably, the most recent RL-based Go agent possesses the unique ability to enhance its skills by playing against itself, a capability not available to human players.
- Autonomous Driving. An autonomous driving system faces the challenge of executing numerous perception and planning functions within an environment characterized by uncertainty. Reinforcement Learning (RL) is employed in various specific tasks, including vehicle path planning and motion prediction. Vehicle path planning entails the use of multiple low and high-level policies to make decisions that span different temporal and spatial scales. On the other hand, motion prediction involves the anticipation of pedestrian and other vehicle movements, thereby enabling an understanding of how the current environmental state might evolve.
Reinforcement learning as field has existed for quite some time but it really gained mainstream popularity after DeepMind’s break through application of Q-learning to play Atari games (Mnih et al. 2013). Since then reinforcement learning has experienced several major breakthroughs and gains in popularity. Unfortunately, this topic is beyond the scope of this book but we recommend Sutton and Barto (2018), Powell (2021), and Szepesvári (2022) to learn more about RL.
1.4 Generative AI
Generative AI represents a category of models that generate content based on user input. It possesses the capability to generate various forms of content, including original images, musical compositions, and humorous jokes. Additionally, it can summarize articles, provide instructions for performing tasks, or even enhance and modify photographs.
Generative AI is versatile in its ability to work with a wide range of inputs and produce diverse outputs, encompassing text, images, audio, and video. Furthermore, it can handle combinations of these input and output types. For instance, a model can take an image as input and generate both an image and accompanying text as output, or it can accept input in the form of an image and text and produce a video as the output.
We can discuss generative models by their inputs and outputs, typically written as “type of input”-to-“type of output.” For example, the following is a partial list of some inputs and outputs for generative models:
- Text-to-text
- Text-to-image
- Text-to-video
- Text-to-code
- Text-to-speech
- Image and text-to-image
Table 1.3 lists example use-cases of generative models.
| Model | Input | Example output |
|---|---|---|
| Text-to-text | Who came up with the michelin star rating for restaurants? | The Michelin star rating system for restaurants was introduced by the French tire company Michelin. The system was first developed in the early 20th century as a means to promote travel and, by extension, the use of automobiles, in order to increase the demand for tires. Michelin began publishing restaurant and hotel guides in 1900, and in 1926, they started awarding stars to restaurants in recognition of their culinary excellence. The Michelin Guide is highly regarded in the culinary world, and Michelin stars have become a prestigious mark of quality for restaurants. [source: ChatGPT ] |
| Text-to-image | A brain riding a rocketship heading towards the moon. |  [source: Imagen ] [source: Imagen ] |
| Text-to-code | Write a hello world statement in R | print("Hello, World!") [source: Bard ] |
| Image-to-text |  |
This is a flamingo. They are found in the Caribbean. [Source: Google DeepMind] |
How does generative AI work? At a high-level, generative models learn patterns in data with the goal to produce new but similar data. To produce unique and creative outputs, generative models are initially trained using an unsupervised approach, where the model learns to mimic the data it’s trained on. The model is sometimes trained further using supervised or reinforcement learning on specific data related to tasks the model might be asked to perform, for example, summarize an article or edit a photo.
Generative AI is a quickly evolving technology with new use cases constantly being discovered. For example, generative models are helping businesses refine their ecommerce product images by automatically removing distracting backgrounds or improving the quality of low-resolution images.
Although this book does not delve into generative AI directly, the deep learning chapters do provide the foundation that many generative AI models are built upon.
1.5 Machine learning in
The ML open-source ecosystem is a vibrant and rapidly evolving collection of software tools, libraries, frameworks, and platforms that are made freely available to the public for building, training, and deploying ML. This ecosystem has played a crucial role in democratizing ML and making ML accessible to a wide range of data scientists, researchers, and organizations.
Although this ecosystem expands multiple programming languages, our focus will predominately be with the R programming language. The R ecosystem provides a wide variety of ML algorithm implementations. This makes many powerful algorithms available at your fingertips. Moreover, there are almost always more than one package to perform each algorithm (e.g., there are over 20 packages for fitting random forests). There are pros and cons to this wide selection; some implementations may be more computationally efficient while others may be more flexible (i.e., have more hyperparameter tuning options).
This book will expose you to many of the R packages and algorithms that perform and scale best to the kinds of data and problems encountered by most organizations while also showing you how to use implementations that provide more consistency.
For example, more recently, development on a group of packages called Tidymodels has helped to make implementation easier. The tidymodels collection allows you to perform discrete parts of the ML workflow with discrete packages:
- rsample for data splitting and resampling
- recipes for data pre-processing and feature engineering
- parsnip for applying algorithms
- tune for hyperparameter tuning
- yardstick for measuring model performance
- and several others!
The tidymodels package is a meta package, or a package of packages, that will install several packages that exist in the tidymodels ecosystem.
Throughout this book you’ll be exposed to several of these packages and more. Moreover, in some cases, ML algorithms are available in one language but not another. As data scientists, we need to be comfortable in finding alternative solutions to those available in our native programming language of choice. Consequently, we may even provide examples of implementations using other languages such as Python or Julia.
Prior to moving on, let’s take the time to make sure you have the required packages installed.
TODO
Once book is complete provide link to DESCRIPTION file or alternative approach for an easy way for readers to install all requirements. Maybe discuss renv??
# data wrangling
install.packages(c("here", "tidyverse"))
# modeling
install.packages("tidymodels")
# model interpretability
install.packages(c("pdp", "vip"))packageVersion("tidymodels")
## [1] '1.3.0'
library(tidymodels)
## ── Attaching packages ────────────────────────────────────── tidymodels 1.3.0 ──
## ✔ broom 1.0.8 ✔ rsample 1.3.0
## ✔ dials 1.4.0 ✔ tibble 3.2.1
## ✔ dplyr 1.1.4 ✔ tidyr 1.3.1
## ✔ infer 1.0.8 ✔ tune 1.3.0
## ✔ modeldata 1.4.0 ✔ workflows 1.2.0
## ✔ parsnip 1.3.2 ✔ workflowsets 1.1.1
## ✔ purrr 1.0.4 ✔ yardstick 1.3.2
## ✔ recipes 1.3.1
## ── Conflicts ───────────────────────────────────────── tidymodels_conflicts() ──
## ✖ purrr::discard() masks scales::discard()
## ✖ dplyr::filter() masks plotly::filter(), stats::filter()
## ✖ dplyr::lag() masks stats::lag()
## ✖ recipes::step() masks stats::step()1.5.1 Knowledge check
1.6 Roadmap
The goal of this book is to provide effective methods and tools for uncovering relevant and useful patterns in your data by using R’s ML stack. We begin by providing an overview of the ML modeling process and discussing fundamental concepts that will carry through the rest of the book. These include feature engineering, data splitting, model validation and tuning, and assessing model performance. These concepts will be discussed more thoroughly in Chapters …
TODO
Fill out roadmap as we progress
1.7 Data sets
TODO
Revisit as we progress
1.8 Exercises
- Identify four real-life applications of supervised and unsupervised problems.
- Explain what makes these problems supervised versus unsupervised.
- For each problem identify the target variable (if applicable) and potential features.
- Identify and contrast a regression problem with a classification problem.
- What is the target variable in each problem and why would being able to accurately predict this target be beneficial to society?
- What are potential features and where could you collect this information?
- What is determining if the problem is a regression or a classification problem?
- Identify three open source data sets suitable for ML (e.g., https://bit.ly/35wKu5c).
- Explain the type of ML models that could be constructed from the data (e.g., supervised versus unsupervised and regression versus classification).
- What are the dimensions of the data?
- Is there a code book that explains who collected the data, why it was originally collected, and what each variable represents?
- If the data set is suitable for supervised learning, which variable(s) could be considered as a useful target? Which variable(s) could be considered as features?
- Identify examples of misuse of ML in society. What was the ethical concern?