Chapter 6 Stacking
Figure .: Super Learner.
6.1 Introduction
Stacking (sometimes called “stacked generalization”) involves training a learning algorithm to combine the predictions of several other learning algorithms. First, all of the other algorithms are trained using the available data, then a combiner algorithm, the metalearner, is trained to make a final prediction using all the predictions of the other algorithms as additional inputs. If an arbitrary metalearning algorithm is used, then stacking can theoretically represent any of the ensemble techniques described in this article, although in practice, a single-layer logistic regression model is often used for metalearning.
Stacking typically yields performance better than any single one of the trained models in the ensemble.
6.2 Background
Leo Breiman, known for his work on classification and regression trees and the creator of the Random Forest algorithm, formalized stacking in his 1996 paper, “Stacked Regressions”. Although the idea originated with David Wolpert in 1992 under the name “Stacked Generalization”, the modern form of stacking that uses internal k-fold cross-validation was Dr. Breiman’s contribution.
However, it wasn’t until 2007 that the theoretical background for stacking was developed, which is when the algorithm took on the name, “Super Learner”. Until this time, the mathematical reasons for why stacking worked were unknown and stacking was considered a “black art.” The Super Learner algorithm learns the optimal combination of the base learner fits. In an article titled, “Super Learner”, by Mark van der Laan et al., proved that the Super Learner ensemble represents an asymptotically optimal system for learning.
6.3 Common Types of Ensemble Methods
In statistics and machine learning, ensemble methods use multiple learning algorithms to obtain better predictive performance than could be obtained by any of the constituent algorithms.
6.3.1 Bagging
- Reduces variance and increases accuracy
- Robust against outliers or noisy data
- Often used with Decision Trees (i.e. Random Forest)
6.3.2 Boosting
- Also reduces variance and increases accuracy
- Not robust against outliers or noisy data
- Flexible - can be used with any loss function
6.3.3 Stacking
- Used to ensemble a diverse group of strong learners
- Involves training a second-level machine learning algorithm called a “metalearner” to learn the optimal combination of the base learners
6.4 The Super Learner Algorithm
A common task in machine learning is to perform model selection by specifying a number of models with different parameters. An example of this is Grid Search. The first phase of the Super Learner algorithm is computationally equivalent to performing model selection via cross-validation. The latter phase of the Super Learner algorithm (the metalearning step) is just training another single model (no cross-validation) on the level one data.
6.4.1 1. Set up the ensemble
- Specify a list of \(L\) base algorithms (with a specific set of model parameters). These are also called base learners.
- Specify a metalearning algorithm (just another algorithm).
6.4.2 2. Train the ensemble
6.4.2.1 Cross-validate Base Learners
- Perform k-fold cross-validation on each of these learners and collect the cross-validated predicted values from each of the \(L\) algorithms.
- The \(N\) cross-validated predicted values from each of the \(L\) algorithms can be combined to form a new \(N \times L\) matrix. This matrix, along wtih the original response vector, is called the “level-one” data.
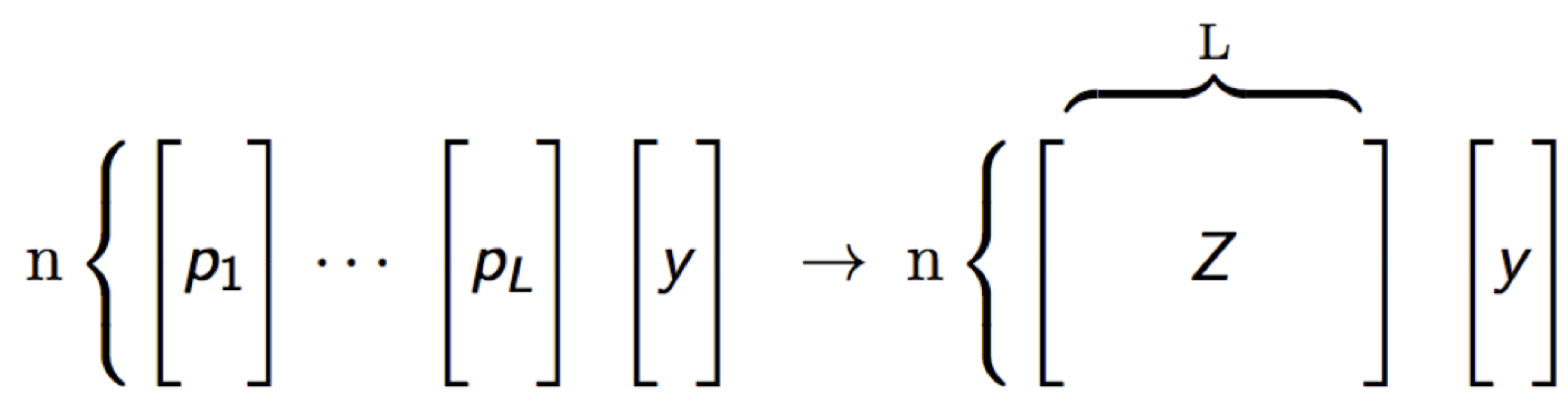
Figure 1.1: Stacking.
6.4.2.2 Metalearning
- Train the metalearning algorithm on the level-one data.
- Train each of the \(L\) base algorithms on the full training set.
- The “ensemble model” consists of the \(L\) base learning models and the metalearning model, which can then be used to generate predictions on a test set.
6.4.3 3. Predict on new data
- To generate ensemble predictions, first generate predictions from the base learners.
- Feed those predictions into the metalearner model to generate the ensemble prediction.
6.5 Stacking Software in R
Stacking is a broad class of algorithms that involves training a second-level “metalearner” to ensemble a group of base learners. The three packages in the R ecosystem which implement the Super Learner algorithm (stacking on cross-validated predictions) are SuperLearner, subsemble and h2oEnsemble.
Among ensemble software in R, there is also caretEnsemble, but it implements a boostrapped (rather than cross-validated) version of stacking via the caretStack() function. The bootstrapped version will train faster since bootrapping (with a train/test) is a fraction of the work as k-fold cross-validation, however the the ensemble performance suffers as a result of this shortcut.
6.5.1 SuperLearner
Authors: Eric Polley, Erin LeDell, Mark van der Laan
Backend: R with constituent algorithms written in a variety of languages
The original Super Learner implemenation is the SuperLearner R package (2010).
Features:
- Implements the Super Learner prediction method (stacking) and contains a library of prediction algorithms to be used in the Super Learner.
- Provides a clean interface to 30+ algorithms in R and defines a consistent API for extensibility.
- GPL-3 Licensed.
6.5.2 subsemble
Authors: Erin LeDell, Stephanie Sapp
Backend: R with constituent algorithms written in a variety of languages
Subsemble is a general subset ensemble prediction method, which can be used for small, moderate, or large datasets. Subsemble partitions the full dataset into subsets of observations, fits a specified underlying algorithm on each subset, and uses a unique form of k-fold cross-validation to output a prediction function that combines the subset-specific fits. An oracle result provides a theoretical performance guarantee for Subsemble.
Features:
- Implements the Subsemble Algorithm.
- Implements the Super Learner Algorithm (stacking).
- Uses the SuperLearner wrapper interface for defining base learners and metalearners.
- Multicore and multi-node cluster support via the snow R package.
- Improved parallelization over the SuperLearner package.
- Apache 2.0 Licensed.
6.5.3 H2O Ensemble
Authors: Erin LeDell
Backend: Java
H2O Ensemble has been implemented as a stand-alone R package called h2oEnsemble. The package is an extension to the h2o R package that allows the user to train an ensemble in the H2O cluster using any of the supervised machine learning algorithms H2O.
Features:
- Uses data-distributed and parallelized Java-based algorithms for the ensemble.
- All training and data processing are performed in the high-performance H2O cluster rather than in R memory.
- Supports regression and binary classification.
- Multi-class support in development.
- Code refactor underway (moving from a separate R package into H2O “proper”) so that the H2O Ensemble interface can be exposed in Python and Scala.
- Apache 2.0 Licensed.
# Install h2oEnsemble from GitHub
install.packages("https://h2o-release.s3.amazonaws.com/h2o-ensemble/R/h2oEnsemble_0.2.1.tar.gz", repos = NULL)
library(h2oEnsemble)6.5.4 Higgs Demo
This is an example of binary classification using the h2o.ensemble function, which is available in h2oEnsemble. This demo uses a subset of the HIGGS dataset, which has 28 numeric features and a binary response. The machine learning task in this example is to distinguish between a signal process which produces Higgs bosons (Y = 1) and a background process which does not (Y = 0). The dataset contains approximately the same number of positive vs negative examples. In other words, this is a balanced, rather than imbalanced, dataset.
If run from plain R, execute R in the directory of this script. If run from RStudio, be sure to setwd() to the location of this script. h2o.init() starts H2O in R’s current working directory. h2o.importFile() looks for files from the perspective of where H2O was started.
6.5.4.1 Start H2O Cluster
h2o.init(nthreads = -1) # Start an H2O cluster with nthreads = num cores on your machine
##
## H2O is not running yet, starting it now...
##
## Note: In case of errors look at the following log files:
## /var/folders/ws/qs4y2bnx1xs_4y9t0zbdjsvh0000gn/T//RtmpLAu9RE/h2o_bradboehmke_started_from_r.out
## /var/folders/ws/qs4y2bnx1xs_4y9t0zbdjsvh0000gn/T//RtmpLAu9RE/h2o_bradboehmke_started_from_r.err
##
##
## Starting H2O JVM and connecting: .. Connection successful!
##
## R is connected to the H2O cluster:
## H2O cluster uptime: 2 seconds 526 milliseconds
## H2O cluster timezone: America/New_York
## H2O data parsing timezone: UTC
## H2O cluster version: 3.18.0.4
## H2O cluster version age: 28 days, 3 hours and 15 minutes
## H2O cluster name: H2O_started_from_R_bradboehmke_kdm557
## H2O cluster total nodes: 1
## H2O cluster total memory: 1.78 GB
## H2O cluster total cores: 4
## H2O cluster allowed cores: 4
## H2O cluster healthy: TRUE
## H2O Connection ip: localhost
## H2O Connection port: 54321
## H2O Connection proxy: NA
## H2O Internal Security: FALSE
## H2O API Extensions: XGBoost, Algos, AutoML, Core V3, Core V4
## R Version: R version 3.4.4 (2018-03-15)
h2o.removeAll() # (Optional) Remove all objects in H2O cluster
## [1] 06.5.4.2 Load Data into H2O Cluster
First, import a sample binary outcome train and test set into the H2O cluster.
# import data
train <- data.table::fread("https://s3.amazonaws.com/erin-data/higgs/higgs_train_10k.csv")
test <- data.table::fread("https://s3.amazonaws.com/erin-data/higgs/higgs_test_5k.csv")
# convert to h2o objects
train <- as.h2o(train)
test <- as.h2o(test)
y <- "response"
x <- setdiff(names(train), y)
family <- "binomial"For binary classification, the response should be encoded as a factor type (also known as the enum type in Java or categorial in Python Pandas). The user can specify column types in the h2o.importFile command, or you can convert the response column as follows:
train[, y] <- as.factor(train[, y])
test[, y] <- as.factor(test[, y])6.5.4.3 Specify Base Learners & Metalearner
For this example, we will use the default base learner library for h2o.ensemble, which includes the default H2O GLM, Random Forest, GBM and Deep Neural Net (all using default model parameter values). We will also use the default metalearner, the H2O GLM.
learner <- c("h2o.glm.wrapper", "h2o.randomForest.wrapper",
"h2o.gbm.wrapper", "h2o.deeplearning.wrapper")
metalearner <- "h2o.glm.wrapper"6.5.4.4 Train an Ensemble
Train the ensemble (using 5-fold internal CV) to generate the level-one data. Note that more CV folds will take longer to train, but should increase performance.
fit <- h2o.ensemble(
x = x, y = y,
training_frame = train,
family = family,
learner = learner,
metalearner = metalearner,
cvControl = list(V = 5)
)6.5.4.5 Evaluate Model Performance
Since the response is binomial, we can use Area Under the ROC Curve (AUC) to evaluate the model performance. Compute test set performance, and sort by AUC (the default metric that is printed for a binomial classification):
perf <- h2o.ensemble_performance(fit, newdata = test)Print the base learner and ensemble performance:
perf
##
## Base learner performance, sorted by specified metric:
## learner AUC
## 1 h2o.glm.wrapper 0.6870611
## 4 h2o.deeplearning.wrapper 0.7524101
## 2 h2o.randomForest.wrapper 0.7686478
## 3 h2o.gbm.wrapper 0.7817084
##
##
## H2O Ensemble Performance on <newdata>:
## ----------------
## Family: binomial
##
## Ensemble performance (AUC): 0.788077753779698We can compare the performance of the ensemble to the performance of the individual learners in the ensemble.
So we see the best individual algorithm in this group is the GBM with a test set AUC of 0.778, as compared to 0.781 for the ensemble. At first thought, this might not seem like much, but in many industries like medicine or finance, this small advantage can be highly valuable.
To increase the performance of the ensemble, we have several options. One of them is to increase the number of internal cross-validation folds using the cvControl argument. The other options are to change the base learner library or the metalearning algorithm.
Note that the ensemble results above are not reproducible since h2o.deeplearning is not reproducible when using multiple cores, and we did not set a seed for h2o.randomForest.wrapper.
If we want to evaluate the model by a different metric, say “MSE”, then we can pass that metric to the print method for and ensemble performance object as follows:
print(perf, metric = "MSE")
##
## Base learner performance, sorted by specified metric:
## learner MSE
## 1 h2o.glm.wrapper 0.2217110
## 4 h2o.deeplearning.wrapper 0.2055667
## 2 h2o.randomForest.wrapper 0.1972701
## 3 h2o.gbm.wrapper 0.1900488
##
##
## H2O Ensemble Performance on <newdata>:
## ----------------
## Family: binomial
##
## Ensemble performance (MSE): 0.1871819023172546.5.4.6 Predict
If you actually need to generate the predictions (instead of looking only at model performance), you can use the predict() function with a test set. Generate predictions on the test set and store as an H2O Frame:
pred <- predict(fit, newdata = test)If you need to bring the predictions back into R memory for futher processing, you can convert pred to a local R data.frame as follows:
predictions <- as.data.frame(pred$pred)[,3] #third column is P(Y==1)
labels <- as.data.frame(test[,y])[,1]The predict method for an h2o.ensemble fit will return a list of two objects. The pred$pred object contains the ensemble predictions, and pred$basepred is a matrix of predictions from each of the base learners. In this particular example where we used four base learners, the pred$basepred matrix has four columns. Keeping the base learner predictions around is useful for model inspection and will allow us to calculate performance of each of the base learners on the test set (for comparison to the ensemble).
6.5.4.7 Specifying new learners
Now let’s try again with a more extensive set of base learners. The h2oEnsemble packages comes with four functions by default that can be customized to use non-default parameters.
Here is an example of how to generate a custom learner wrappers:
h2o.glm.1 <- function(..., alpha = 0.0) h2o.glm.wrapper(..., alpha = alpha)
h2o.glm.2 <- function(..., alpha = 0.5) h2o.glm.wrapper(..., alpha = alpha)
h2o.glm.3 <- function(..., alpha = 1.0) h2o.glm.wrapper(..., alpha = alpha)
h2o.randomForest.1 <- function(..., ntrees = 200, nbins = 50, seed = 1) h2o.randomForest.wrapper(..., ntrees = ntrees, nbins = nbins, seed = seed)
h2o.randomForest.2 <- function(..., ntrees = 200, sample_rate = 0.75, seed = 1) h2o.randomForest.wrapper(..., ntrees = ntrees, sample_rate = sample_rate, seed = seed)
h2o.randomForest.3 <- function(..., ntrees = 200, sample_rate = 0.85, seed = 1) h2o.randomForest.wrapper(..., ntrees = ntrees, sample_rate = sample_rate, seed = seed)
h2o.randomForest.4 <- function(..., ntrees = 200, nbins = 50, balance_classes = TRUE, seed = 1) h2o.randomForest.wrapper(..., ntrees = ntrees, nbins = nbins, balance_classes = balance_classes, seed = seed)
h2o.gbm.1 <- function(..., ntrees = 100, seed = 1) h2o.gbm.wrapper(..., ntrees = ntrees, seed = seed)
h2o.gbm.2 <- function(..., ntrees = 100, nbins = 50, seed = 1) h2o.gbm.wrapper(..., ntrees = ntrees, nbins = nbins, seed = seed)
h2o.gbm.3 <- function(..., ntrees = 100, max_depth = 10, seed = 1) h2o.gbm.wrapper(..., ntrees = ntrees, max_depth = max_depth, seed = seed)
h2o.gbm.4 <- function(..., ntrees = 100, col_sample_rate = 0.8, seed = 1) h2o.gbm.wrapper(..., ntrees = ntrees, col_sample_rate = col_sample_rate, seed = seed)
h2o.gbm.5 <- function(..., ntrees = 100, col_sample_rate = 0.7, seed = 1) h2o.gbm.wrapper(..., ntrees = ntrees, col_sample_rate = col_sample_rate, seed = seed)
h2o.gbm.6 <- function(..., ntrees = 100, col_sample_rate = 0.6, seed = 1) h2o.gbm.wrapper(..., ntrees = ntrees, col_sample_rate = col_sample_rate, seed = seed)
h2o.gbm.7 <- function(..., ntrees = 100, balance_classes = TRUE, seed = 1) h2o.gbm.wrapper(..., ntrees = ntrees, balance_classes = balance_classes, seed = seed)
h2o.gbm.8 <- function(..., ntrees = 100, max_depth = 3, seed = 1) h2o.gbm.wrapper(..., ntrees = ntrees, max_depth = max_depth, seed = seed)
h2o.deeplearning.1 <- function(..., hidden = c(500,500), activation = "Rectifier", epochs = 50, seed = 1) h2o.deeplearning.wrapper(..., hidden = hidden, activation = activation, seed = seed)
h2o.deeplearning.2 <- function(..., hidden = c(200,200,200), activation = "Tanh", epochs = 50, seed = 1) h2o.deeplearning.wrapper(..., hidden = hidden, activation = activation, seed = seed)
h2o.deeplearning.3 <- function(..., hidden = c(500,500), activation = "RectifierWithDropout", epochs = 50, seed = 1) h2o.deeplearning.wrapper(..., hidden = hidden, activation = activation, seed = seed)
h2o.deeplearning.4 <- function(..., hidden = c(500,500), activation = "Rectifier", epochs = 50, balance_classes = TRUE, seed = 1) h2o.deeplearning.wrapper(..., hidden = hidden, activation = activation, balance_classes = balance_classes, seed = seed)
h2o.deeplearning.5 <- function(..., hidden = c(100,100,100), activation = "Rectifier", epochs = 50, seed = 1) h2o.deeplearning.wrapper(..., hidden = hidden, activation = activation, seed = seed)
h2o.deeplearning.6 <- function(..., hidden = c(50,50), activation = "Rectifier", epochs = 50, seed = 1) h2o.deeplearning.wrapper(..., hidden = hidden, activation = activation, seed = seed)
h2o.deeplearning.7 <- function(..., hidden = c(100,100), activation = "Rectifier", epochs = 50, seed = 1) h2o.deeplearning.wrapper(..., hidden = hidden, activation = activation, seed = seed)Let’s grab a subset of these learners for our base learner library and re-train the ensemble.
6.5.4.8 Customized base learner library
learner <- c(
"h2o.glm.wrapper",
"h2o.randomForest.1",
"h2o.randomForest.2",
"h2o.gbm.1",
"h2o.gbm.6",
"h2o.gbm.8",
"h2o.deeplearning.1",
"h2o.deeplearning.6",
"h2o.deeplearning.7"
)Train with new library:
fit <- h2o.ensemble(
x = x, y = y,
training_frame = train,
family = family,
learner = learner,
metalearner = metalearner,
cvControl = list(V = 5)
)Evaluate the test set performance:
perf <- h2o.ensemble_performance(fit, newdata = test)We see an increase in performance by including a more diverse library.
Base learner test AUC (for comparison)
perf
##
## Base learner performance, sorted by specified metric:
## learner AUC
## 1 h2o.glm.wrapper 0.6870611
## 8 h2o.deeplearning.6 0.7250912
## 7 h2o.deeplearning.1 0.7304767
## 9 h2o.deeplearning.7 0.7422359
## 2 h2o.randomForest.1 0.7798627
## 6 h2o.gbm.8 0.7804816
## 4 h2o.gbm.1 0.7805141
## 3 h2o.randomForest.2 0.7821736
## 5 h2o.gbm.6 0.7825354
##
##
## H2O Ensemble Performance on <newdata>:
## ----------------
## Family: binomial
##
## Ensemble performance (AUC): 0.789971483845538So what happens to the ensemble if we remove some of the weaker learners? Let’s remove the GLM and DL from the learner library and see what happens…
Here is a more stripped down version of the base learner library used above:
learner <- c(
"h2o.randomForest.1",
"h2o.randomForest.2",
"h2o.gbm.1",
"h2o.gbm.6",
"h2o.gbm.8"
)Again re-train the ensemble and evaluate the performance:
fit <- h2o.ensemble(
x = x, y = y,
training_frame = train,
family = family,
learner = learner,
metalearner = metalearner,
cvControl = list(V = 5)
)
perf <- h2o.ensemble_performance(fit, newdata = test)We actually lose ensemble performance by removing the weak learners! This demonstrates the power of stacking with a large and diverse set of base learners.
perf
##
## Base learner performance, sorted by specified metric:
## learner AUC
## 1 h2o.randomForest.1 0.7798627
## 5 h2o.gbm.8 0.7804816
## 3 h2o.gbm.1 0.7805141
## 2 h2o.randomForest.2 0.7821736
## 4 h2o.gbm.6 0.7825354
##
##
## H2O Ensemble Performance on <newdata>:
## ----------------
## Family: binomial
##
## Ensemble performance (AUC): 0.787453857322699At first thought, you may assume that removing less performant models would increase the perforamnce of the ensemble. However, each learner has it’s own unique contribution to the ensemble and the added diversity among learners usually improves performance. The Super Learner algorithm learns the optimal way of combining all these learners together in a way that is superior to other combination/blending methods.
6.5.5 Stacking Existing Model Sets
You can also use an existing (cross-validated) list of H2O models as the starting point and use the h2o.stack() function to ensemble them together via a specified metalearner. The base models must have been trained on the same dataset with same response and for cross-validation, must have all used the same folds.
An example follows. As above, start up the H2O cluster and load the training and test data.
Cross-validate and train a handful of base learners and then use the h2o.stack() function to create the ensemble:
# The h2o.stack function is an alternative to the h2o.ensemble function, which
# allows the user to specify H2O models individually and then stack them together
# at a later time. Saved models, re-loaded from disk, can also be stacked.
# The base models must use identical cv folds; this can be achieved in two ways:
# 1. they be specified explicitly by using the fold_column argument, or
# 2. use same value for `nfolds` and set `fold_assignment = "Modulo"`
nfolds <- 5
glm1 <- h2o.glm(
x = x, y = y,
family = family,
training_frame = train,
nfolds = nfolds,
fold_assignment = "Modulo",
keep_cross_validation_predictions = TRUE
)
gbm1 <- h2o.gbm(
x = x, y = y,
distribution = "bernoulli",
training_frame = train,
seed = 1,
nfolds = nfolds,
fold_assignment = "Modulo",
keep_cross_validation_predictions = TRUE
)
rf1 <- h2o.randomForest(
x = x, y = y, # distribution not used for RF
training_frame = train,
seed = 1,
nfolds = nfolds,
fold_assignment = "Modulo",
keep_cross_validation_predictions = TRUE
)
dl1 <- h2o.deeplearning(
x = x, y = y,
distribution = "bernoulli",
training_frame = train,
nfolds = nfolds,
fold_assignment = "Modulo",
keep_cross_validation_predictions = TRUE
)
models <- list(glm1, gbm1, rf1, dl1)
metalearner <- "h2o.glm.wrapper"
# stack existing models
stack <- h2o.stack(
models = models,
response_frame = train[,y],
metalearner = metalearner,
seed = 1,
keep_levelone_data = TRUE
)
# Compute test set performance:
perf <- h2o.ensemble_performance(stack, newdata = test)Print base learner and ensemble test set performance:
print(perf)
##
## Base learner performance, sorted by specified metric:
## learner AUC
## 1 GLM_model_R_1522981883987_9864 0.6870611
## 4 DeepLearning_model_R_1522981883987_11012 0.7248477
## 3 DRF_model_R_1522981883987_10450 0.7691438
## 2 GBM_model_R_1522981883987_9882 0.7817084
##
##
## H2O Ensemble Performance on <newdata>:
## ----------------
## Family: binomial
##
## Ensemble performance (AUC): 0.7876274479047266.5.5.1 All done, shutdown H2O
# good practice
h2o.shutdown(prompt = FALSE)
## [1] TRUE